
新智元报说念

[新智元导读]Anthropic自家工程师早已基本不写代码了,却280好意思元一个任务,费钱请约1000名外部工程师,手把手教ClaudeCode写出好代码。喂养前沿模子的,终究如故东说念主。
最近,一篇报说念把ClaudeCode的「高出秘笈」摆在了台面上。
BusinessInsider称,Anthropic有一个专门普及ClaudeCode的技俩,正在通过约1000名软件工程师的反映来打磨它。
这个技俩在数据公司SnorkelAI里面,代号为「Marlin」。

早在本年1月,ClaudeCode负责东说念主BorisCherny就爆料我方照旧两个多月没手写过一转代码,一天就让Claude提交22个拉取肯求(PullRequest),前一天则提交了27个,全是模子写的。
也有报说念称,Anthropic里面代码也大部分由AI生成。
道理的处所,正在这儿。
一边,Anthropic自家中枢工程师照旧把广泛编码使命交给模子;另一边,它在费钱请约1000名外部工程师,手把手教ClaudeCode什么才叫「好代码」。
一小时280好意思元
买的到底是什么
按BusinessInsider的说法,Marlin技俩请的外部工程师都有软件工程配景。他们的活儿,听上去很像一次真实的代码评审。
经由概况是这么。先从一份包含数千个仓库的清单里,选一个GitHub的代码仓库。然后建一个PR,也即是开发者提移交码修改的那一步。再写一段指示词,把任务解说晰。
模子会生成两套代码,而这些外部工程师接下来要作念的,是A/B测试:比较两套输出,选出更好的那一套。
每个任务报恩280好意思元,简陋花一小时。有些还要和Snorkel的审核层往复好几轮。
评判的圭臬,是评估坐褥级代码的正确性、安全性、可靠性和可人戴性。
举两个真实的例子。
在一个任务里,外部工程师让模子重构系统处理奉行元数据(executionmetadata)的步地,谋略是让代码更澄澈、更好爱戴,但不改变功能。
另一个任务中,外部工程师给MLflow这个开源机器学习平台作念安全开辟,针对它加载模子时下载Python包可能出现的敕令注入粗心。材料的条款特殊明确:既要挡住敕令注入,又不行误伤正当的pip(Python包管束器)选项。
这些任务的条款,照旧超出了数据标注的鸿沟,更像是要让一个资深工程师,把脑子里那套「这么写更好」的判断原样拷给模子。
昭着,Anthropic购买的并非代码,而是资深智商员头脑中阿谁如何把代码写得更安全、更干净的判断。
为什么非得是工程师
Anthropic为什么要如斯大费周章?因为ClaudeCode早就不是一个写代码的聊天框了。
Anthropic官方把它界说为技俩级的AI智能体。它能读完扫数这个词代码库,跨文献作念打算,平直奉行修改,跑测试,再凭证失败的成果我方迭代。

Anthropic官网对ClaudeCode的界说:一套能读代码库、跨文献转变、跑测试、委用已提移交码的智能体。
这意味着它会确切动手改文献、跑任务,战争扫数这个词代码工程。
Anthropic我方也明晰这件事的重量,因此在工程博客里反复讲ClaudeCode的权限、沙箱和批准疲惫(approvalfatigue)问题。
默许情况下,高风险文献修改或敕令奉行需要用户批准;为减少反复授权带来的批准疲惫,Anthropic还引入了sandboxing,让ClaudeCode在预设文献系统和汇集界限内更安全地起程点。
当一个AI能跑敕令、能动线上代码,犯错的代价就皆备不雷同了。践诺谋略也随着变:从「写对」升级到「写得安全、可靠、可人戴」。
这些东西,凡俗的代码语料喂不出来。它往时藏在资深工程师的代码审查里,是东说念主传东说念主的训戒。面前,Anthropic想通过招募东说念主类编程人人,把它酿成不错购买的数据。
Snorkel
被低估的「数据军火商」
整件事情的着实主角是Snorkel。
这家公司2019年从斯坦福AILab走出来,押注的标的唯唯一个:着实决定机器学习成败的是数据,而不是模子或者算力。
Snorkel的两位抨击创举东说念主是AlexRatner和他在斯坦福的导师ChrisRé,他们说Snorkel的中枢学术源泉。

SnorkelAI纠合创举东说念主、CEOAlexRatner
2015年,Snorkel还仅仅Ratner读博时的一个「下昼技俩」:与其花大价格雇东说念主一条条标数据,不如用智商和划定作念「弱监督」(weaksupervision),让模子不靠东说念主工逐条标注也能学。
靠着这套想路,Snorkel攒下60多篇论文,开源器具也被Google、Intel用了起来,直到2019年才负责拆分红公司。

SnorkelAI纠合创举东说念主,斯坦福教训ChrisRé
Ratner的导师ChrisRé亦然个狠脚色。
他是斯坦福教训、麦克阿瑟天才奖得主、衔接创业者,参与的技俩曾被苹果收购,还创办了估值一度达50亿好意思元的SambaNova。
最有真谛的如故这家公司的回身。
Snorkel当年要破的,恰是「东说念主工标注又慢、又贵、又不稳」这个老浩劫,当时AI开发约80%的时辰都耗在手工标注数据上,因此Snorkel率先的盼望,即是尽量把东说念主从标注里目田出来。
可到了前沿模子期间,最稀缺、最值钱的又回到了东说念主身上,仅仅换成了博士、大夫、讼师、资深工程师等人人的品尝和判断。这家靠「少用东说念主」起家的公司,如今最赢利的买卖反倒是组织一支不菲的人人雄兵去践诺前沿AI,kaiyun体育(中国)2026世界杯Marlin仅仅其中一单。
它的使命流,刚好也呼应了Marlin技俩的需求。
Snorkel官网这么形色这套使命流:先界说任务、评分圭臬和考证器,框定「什么算好」,再跑人人评审活水线,作家、多名评审、最终裁决者层层把关,全程留痕。
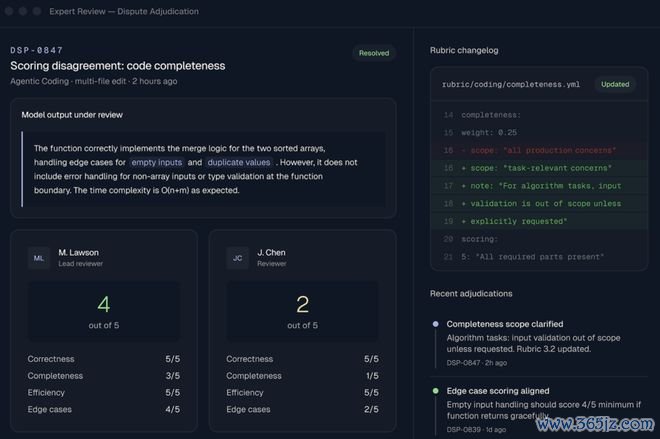
Snorkel官网知道:评审打分出现不对后经裁决责罚,并写入评分圭臬变更纪录,每处转变都可牵挂到谁、何时、依据什么。
它还会把评估环境和数据一并搭好,让统一批任务能在不同模子版块上反复跑,得出可复现、可比较的分数。而要让分数干净可比,评分的东说念主就不行受版块干豫。这些外部工程师不知说念我方评的是哪个版块,原因就在这儿。
报价也很能诠释问题。
Snorkel一个公开的法律标的条约岗,每个高质料任务10到100好意思元;而Marlin的软件工程任务是280好意思元一个、约一小时,折成时薪差未几是同业的两倍半(ScaleAI、Mercor给工程师开到每小时110好意思元)。顶尖人人周入还能卓著3000好意思元。
Snorkel招募的这些外部工程师的反映,是确切贵。
客户名单里有Google、Mistral、Anthropic。2025年5月,Snorkel完成D轮融资,估值13亿好意思元。
Anthropic营收负责东说念主KateJensen知道,要把Claude的后劲皆备开释出来,得靠引入领域人人和东说念主类反映的新评估递次,Anthropic会络续和Snorkel这么的公司配合。
Snorkel、Scale、Mercor这些公司,往时被当成「标注平台」。如今它们成了前沿模子公司背后的隐形供应链。
给最机灵的AI喂料的,即是这么一支区别各人、看不见的人人雄兵。
几个巨头
抢的是统一种数据
不仅仅Anthropic在买真实工程才略。这场竞赛,几个重磅玩家都在参与,仅仅打法不同。
Cursor走的是家具数据这条路。
它官方写明:用户开启躲避模式后,代码毫不会被它或第三方用于践诺;唯独关闭躲避模式,它才可能用代码库数据、指示词、裁剪行径、代码片断,来立异AI功能、践诺模子。
Cursor的Tab模子每天产出卓著10亿个裁剪字符,肯求量比第一版涨了约100倍。更进一步的Composer,通过强化学习(RL)践诺,让模子在广泛代码任务环境中学习调用裁剪、搜索等器具,处理更长周期的工程任务。
到最新的Composer2.5,干脆主攻需要数百步操作的长周期任务。
马斯克采纳的是老本绑定/收购期权的步地。
2026美加墨世界杯中国官方网页版本年2月,xAI并入SpaceX。4月底,SpaceX拿下了年内以600亿好意思元收购Cursor母公司Anysphere的权益,或者先付100亿好意思元作念深度配合。马斯克看中的恰是Cursor手里那份各人最活跃的真实开发者行径数据。
5月25日,马斯克在X上秘书,新一代基础模子GrokV9-Medium践诺完成,参数1.5T,是刻下坐褥模子的3倍。他迥殊点出,这如故没加Cursor数据补训之前的收获,加完「编程才略会强许多」,模子展望6月中旬发布。

这么一来,V9会是第一个系统性地「吃过」真实开发者行径数据的Grok。
OpenAI其后的Codex也走上了这条路。2025年发布的Codex由codex-1驱动,OpenAI称其是在真实编码任务上通过强化学习践诺的,谋略是写出迫临东说念主类作风、合适PR民俗的代码,还能反复跑测试直到通过;每个任务跑在预装了你代码库的糟蹋沙箱里。
如今Codex已升级为OpenAI的agenticcoding平台,由其前沿编码模子驱动;据Axios报说念,每周用户已卓著500万。
他们争夺的,其实是统一种东西:过程数据,仅仅旅途各不疏导。
Anthropic先有模子,缺真实开发现场的反映,就费钱请约1000名工程师,把软件工程过程拆成可学习的数据;
Cursor先有家具和真实用户行径,也有自研的Tab、Composer等编程模子。但比较OpenAI、Anthropic,它更缺的是通用基础模子底座和大规模践诺算力;
马斯克缺的亦然数据,干脆试图用几百亿好意思元去买一个络续产生开发者行径数据的家具进口;
OpenAI模子、家具两端都不缺,于是我方搭沙箱,让模子在真实编码任务里通过强化学习一遍遍试错、测试、修正、迭代。
几家打法不同,同归殊途,都在用越来越接近真实工程现场的数据,来践诺我方的AI编程模子。

着实的护城河
是东说念主的品尝和判断
有一篇叫SWE-chat的论文,第一次大规模会聚了真实的智能体编码会话:6000段、卓著6.3万条用户prompt、35.5万次器具调用。
它得出一个扎心的数字:智能体产出的代码,唯独44%最终参预了用户的提交里。有一半多的气运被东说念主删了、改了、推翻了。
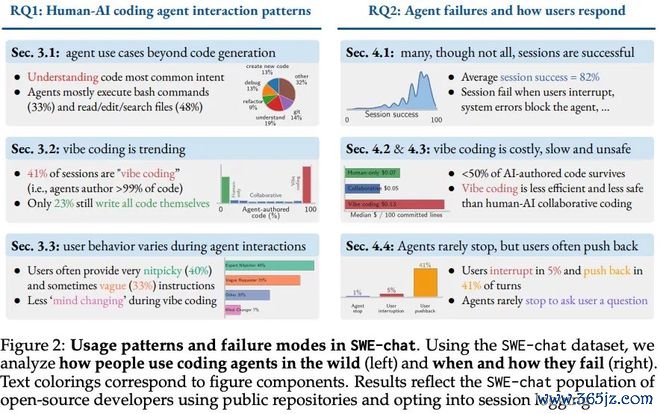
SWE-chat实测:vibecoding已占41%的会话,但智能体写的代码唯独44%最终参预提交;用户在44%的交互轮次里通过立异、报错或中断来反推模子输出。
这诠释,HumanEval那类老的基准测试(benchmark)照旧刷到富余,光看跑分真谛不大了。着实的战场,是真实开发过程里那些反复、试错、推翻重来的数据。
模子越强,越要费钱去买东说念主类还没被替代的那部分东西:工程直观。
Anthropic花280好意思元一个任务,请来约1000名工程师作念A/B投票:这套看上去繁难的活儿,买的恰是这少量。
谁能把工程现场酿成模子能消化的数据kaiyun云开体育,谁就抓住了参预AI编程下一程的入场券。